Obviously without tests or anything, but just using ets with front/rear counters.
-module(shq).
-export([init/1,
in/2,
in_r/2,
out/1,
out_r/1,
size/1]).
init(Tab) ->
Ref = ets:new(Tab, [public, set]),
ets:insert(Ref, [{front, 0}, {rear, 0}]),
{ok, Ref}.
in(Ref, Value) ->
true = ets:insert(Ref, {ets:update_counter(Ref, rear, 1) - 1, Value}),
ok.
in_r(Ref, Value) ->
true = ets:insert(Ref, {ets:update_counter(Ref, front, -1), Value}),
ok.
out(Ref) ->
KF = ets:update_counter(Ref, front, 1) - 1,
case ets:take(Ref, KF) of
[{_, V}] ->
{ok, V};
[] ->
empty
end.
out_r(Ref) ->
KR1 = ets:update_counter(Ref, rear, -1),
case ets:take(Ref, KR1) of
[{_, V}] ->
{ok, V};
[] ->
empty
end.
size(Ref) ->
ets:lookup_element(Ref, rear, 2) - ets:lookup_element(Ref, front, 2).
Using the suggested utTc module above to test.
In both tests 1_000_000 entries were add into the table before running.
> utTc:tm(1000,100,shq, out, [T]).
=====================
execute Args:[#Ref<0.2264322891.2797469697.147954>]
execute Fun :out
execute Mod :shq
execute LoopTime:100
execute ProcCnts:1000
PMaxTime: 12487019(ns) 0.012487(s)
PMinTime: 328385(ns) 0.000328(s)
PSumTime: 3748337374(ns) 3.748337(s)
PAvgTime: 3748337.37(ns) 0.003748(s)
FAvgTime: 37483.3737(ns) 0.000037(s)
PGrar : 397(cn) 0.40(%)
PLess : 603(cn) 0.60(%)
=====================
and for comparison, the original gen_server based shq module (named shq2 locally)
utTc:tm(1000,100,shq2, out, [Ref]).
=====================
execute Args:[<0.89.0>]
execute Fun :out
execute Mod :shq2
execute LoopTime:100
execute ProcCnts:1000
PMaxTime: 353619294(ns) 0.353619(s)
PMinTime: 348715711(ns) 0.348716(s)
PSumTime: 3514640250(ns) 351.464025(s)
PAvgTime: 351464025.(ns) 0.351464(s)
FAvgTime: 3514640.25(ns) 0.003515(s)
PGrar : 507(cn) 0.51(%)
PLess : 493(cn) 0.49(%)
=====================
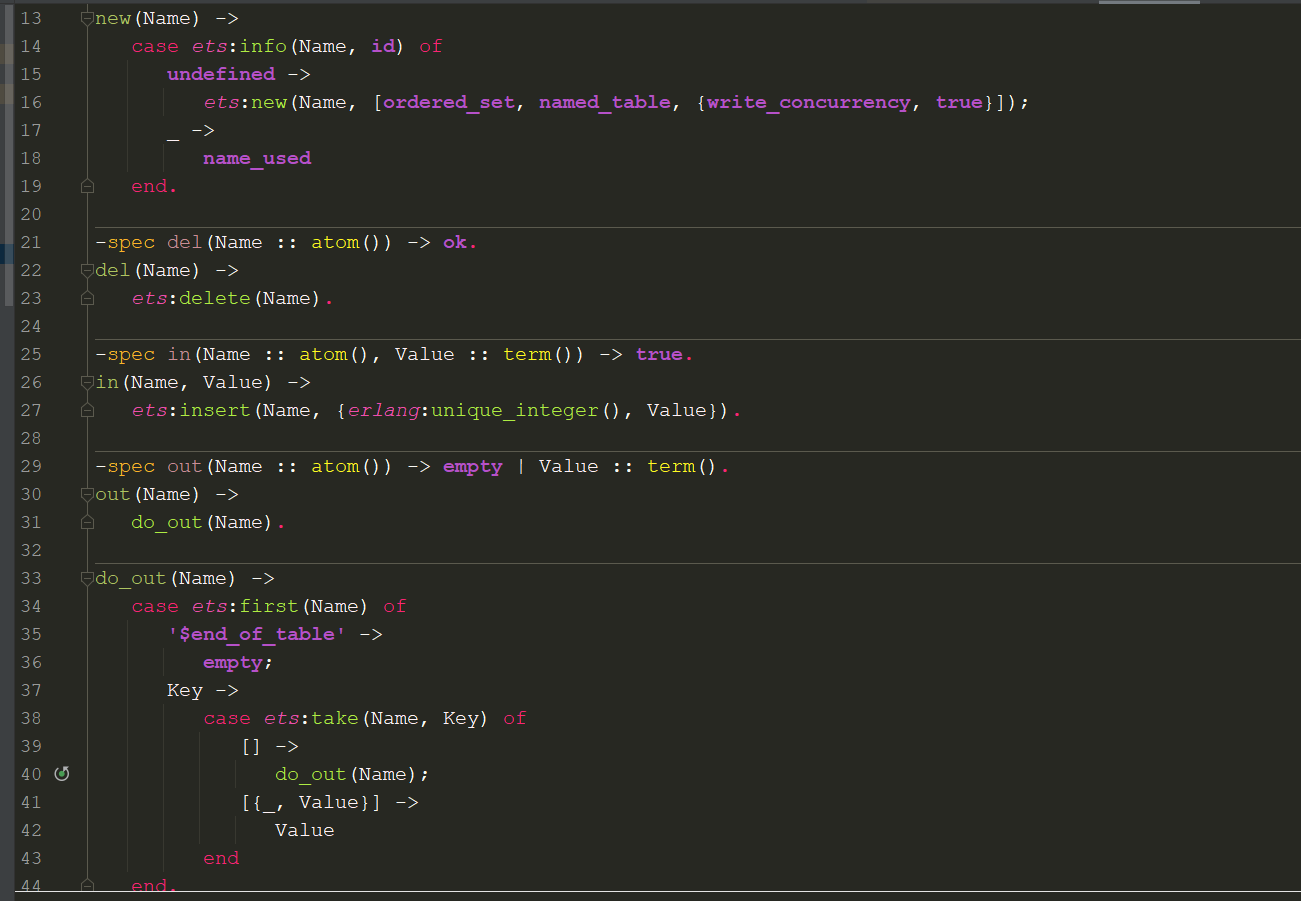
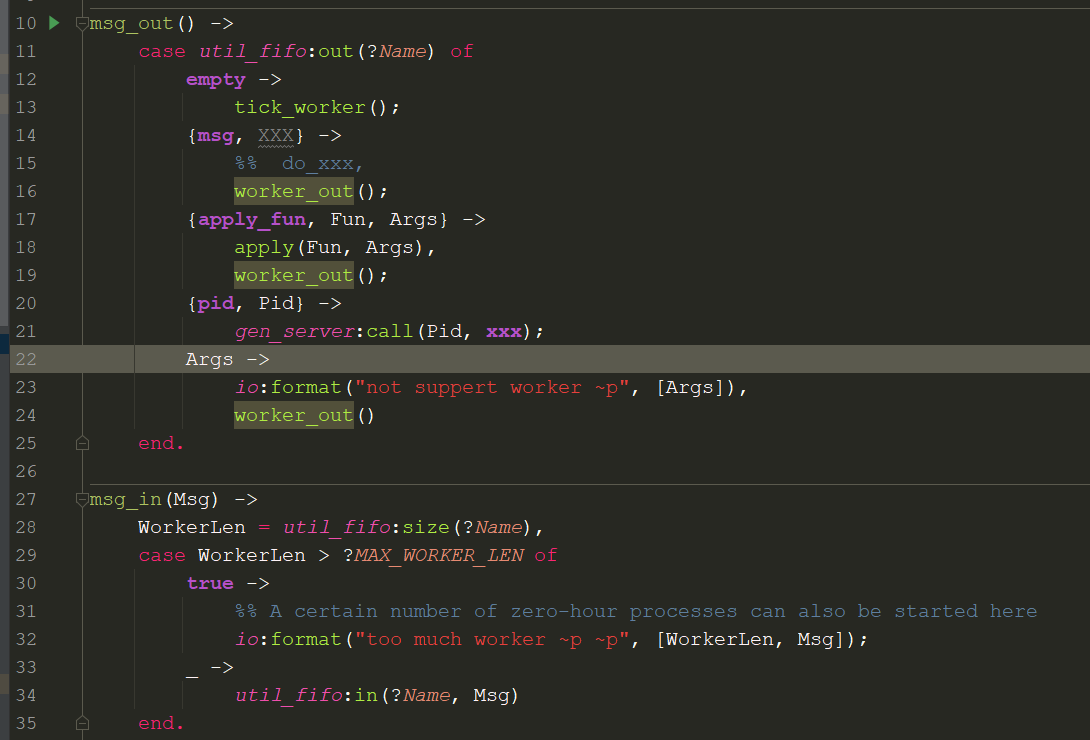

 But I can’t imagine what for, so please tell me
But I can’t imagine what for, so please tell me  ).
).