I (RabbitMQ/Ra) has a resource profile where lots of entries are written and read from an ETS (set) table. Each key is unique so the table will grow in size until it reaches some limit, at which point it will be deleted. Often the terms written contain binaries that get allocated on the large binary heap. This pattern results in a saw=tooth like memory profile.
I’m wondering what memory allocator (ETS and binary) tweaks I should try for this kind of profile. I tried using the erts_alloc_config tool and it spat out the following config but I am not sure it captured the saw tooth memory use pattern very well.
The main issue I have is that the whole system seems to degrade substantially when the ETS tables are deleted. Our tests see a regular though-put dip and if I amend the code so that the ETS tables are not deleted this dip is reduced or almost completely go away. I am guessing it has something to do with the amount of work done when freeing all that memory. Any advice would be greatly appreciated of course.
erts_alloc_config has not been updated in quite a while, so the results you get from it will most likely not help you.
How easy is it for you to reproduce? Have you measured microstate accounting stats during the throughput dip? with extra statistics counters? What about running perf while the problem is happening?
From what you have described so far, nothing points towards this being a problem that can be solved by tuning the memory allocators.
I have used lcnt, msacc (with extras) and profiled with perf but there is nothing sticking out (I can re-run and prepare output if worthwhile). All I can see from perf is that deleting an ETS table with ~600k entries (+ the same number of 256 byte binaries) is an expensive operation. It takes around 350ms on my linux box. This is fair enough but I don’t see why it should affect the rest of the system as much as it does on a fast multi-core machine. At the point the ETS table is being deleted it is no longer read or written to by any other process so there should not be any contention there that would block it. The table uses write_concurrency. The delete happens by a dedicated owner process that is never called into.
Because I can’t see anything else and the process does de-allocate a lot of data quickly is why I wanted to see if there were more optimal allocator settings for this kind of use case but I’ll take any further advice on anything
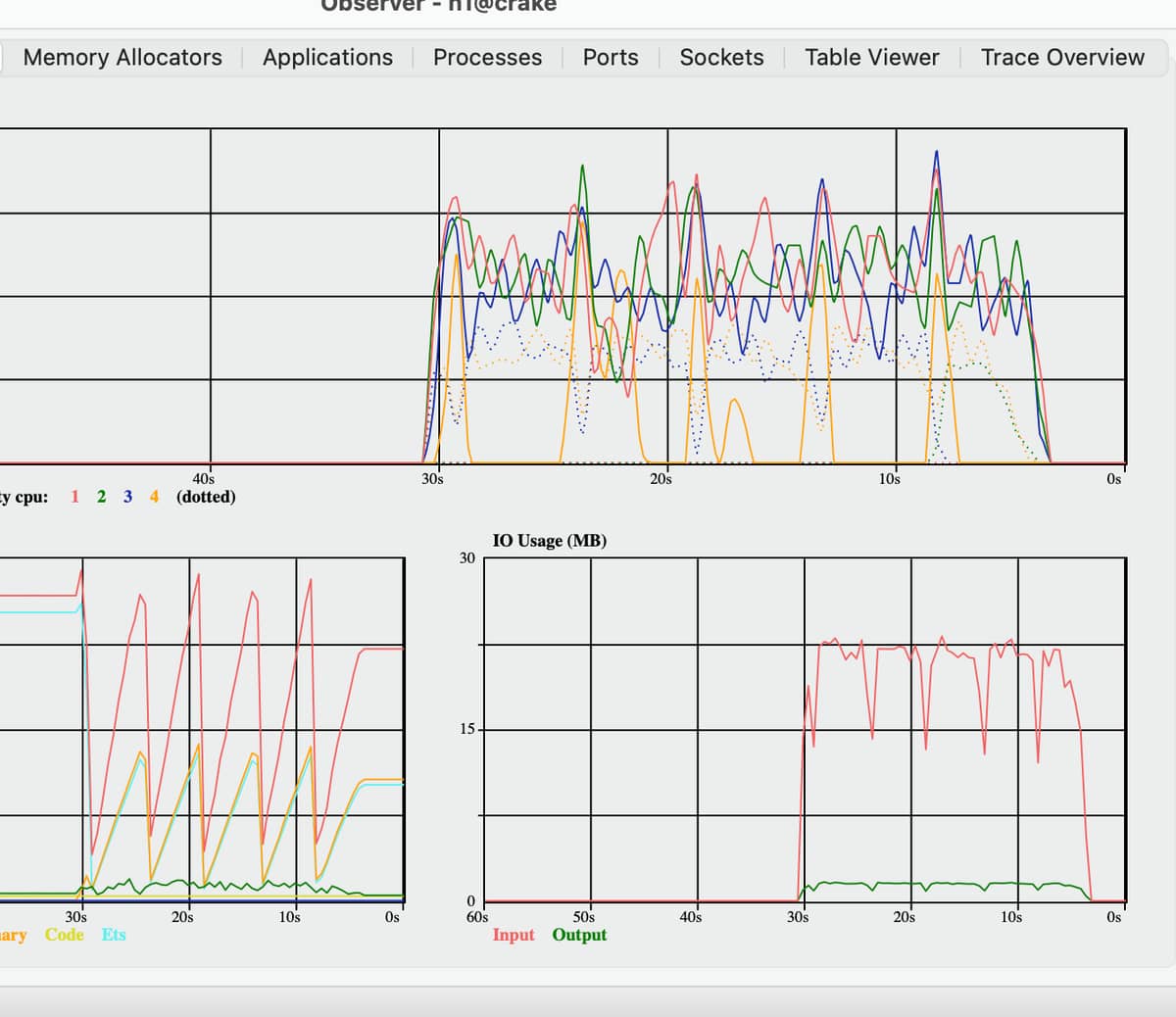
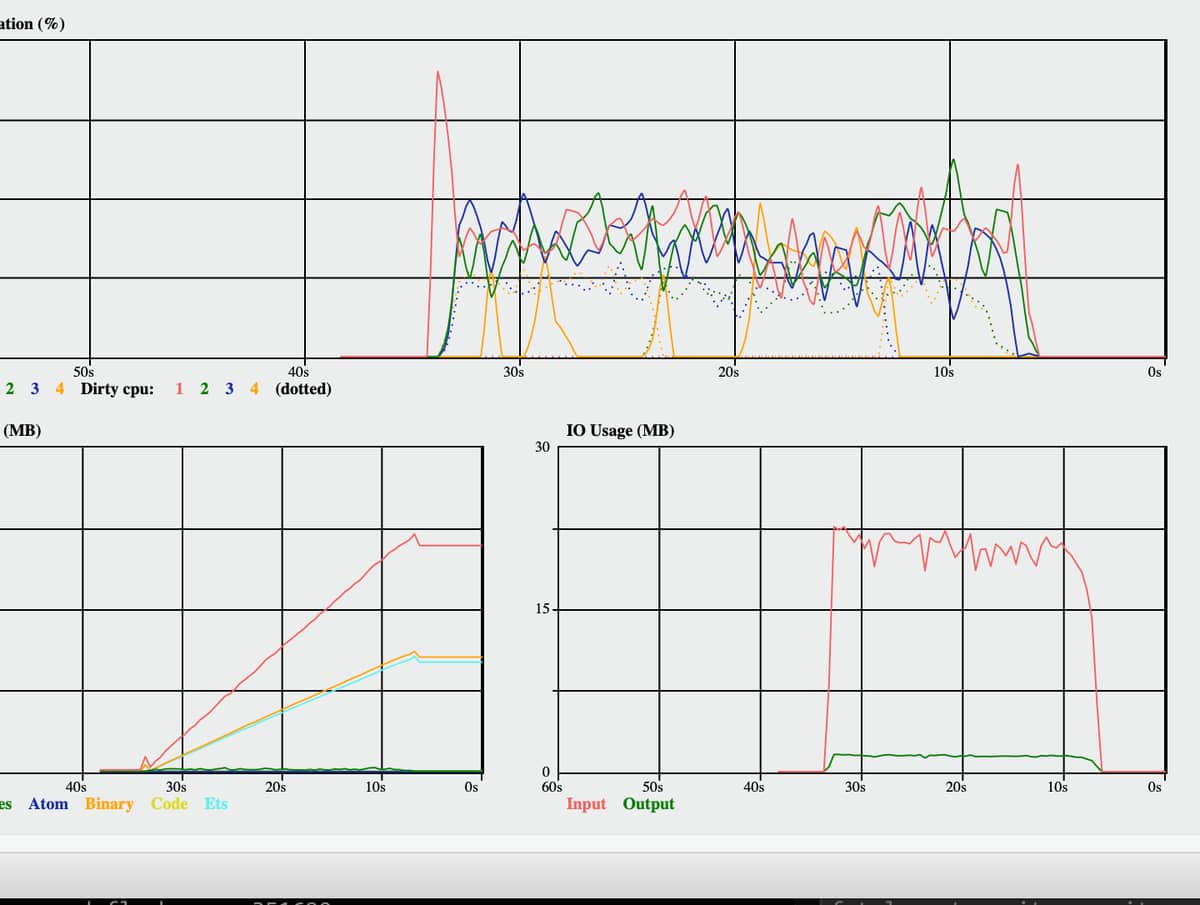
Good idea. Just tried it but it behaves similarly. Here is the Load Chart for the run (with a lower process priority). the IO usage is pretty much what we see from the system from the outside too.
If it is the deletion that interferes with operations, maybe it is a good idea to slow that deletion down by doing it manually? That is deleting elements manually from the table before dropping the table?
Besides that, the only thing I can think of is to use an allocation strategy with a smaller overhead, which would be something like gf (goodfit) or ageffcaoff (age order first fit carrier address order first fit). Not sure if it will make any large difference though.
I tried getting all the keys then deleting them one by one which made overall table delete times about twice as long but this made the system perform worse overall. I then inserted an erlang:yield/0 in between each ets:delete/2 and this made it so slow it did actually even out the work but ultimately made overall throughput a lot worse and choppy. I don’t think this is a scheduling issue as there is plenty of capacity to run stuff.
I then tried all the allocation strategies in turn and apart from aoffcbf, ageffcbf and gf they tended to make ets:delete/1 slower and affect the system more, which is interesting in itself.
A couple of data points which I don’t know if they change anything: The process that writes to the ETS tables isn’t the process that deletes them. There are a lot of ETS writes to other tables whilst older tables are being deleted.
When deallocation of memory happens, the block that represented that memory has to be sent to the original scheduler that allocated the block. This is done through a queue in between schedulers. Handling of that queue would show up as “other”. If you deallocate a lot of items, then there will be a lot of messages sent in between schedulers.
One theory about what is happening is that it is handling of the memory deallocations that effect the throughput. There is no config option to change the priority of handling that work in relation to running processes.
There is no logic that specifically takes it into account, but since almost all of the scheduler balancing is done through work-stealing I think that it should balance itself out.
I did some quick digging and it seems like my hypothesis regarding delated de-alloc is correct. When running perf just as the ets:delete happens there is a lot of handle_delayed_dealloc calls happening.
The number of ops/sec that I got fluctuated a lot more than what you have in your example though, so not sure if I would draw too many conclusions from my tests.
Thank you for testing this. There are many other variables, disk speeds etc that affect the throughput variability apart from the ets:delete/1 but on my system I can’t see anything else poke out obviously.
If you think if anything else we could try to mitigate the impact of this I’m all ears!
I talked a bit with the team and we don’t have any great suggestions about how to solve this. There is a lot of work that needs to be done when deallocating such a large table.
Some ideas that may not work for you are:
Make the table smaller… smaller table means less work to be done at once
Make the binary into a list, will halve the number of deallocation, but use more memory. (You could also split the binary into 63 bytes chunks if that is better…).
Create a process using a min_heap_size that can fit the cache. Though you still will get the deallocations for the binaries, unless you combine this with suggestion 2.
Bind the process doing ets:insert and ets:delete to a scheduler using the undocumented and unsupported spawn_opt(M,F,A,[{scheduler,1}]). I don’t really recommend doing this, as it may have other nasty side effects, but could be fun to try and see if it helps.
Thanks for remembering I asked about this and bringing it up.
We do play around with smaller tables and it does help a bit but there is another tradeoff in play as well where we don’t want the tables to get too small as then we may end up with greater than necessary write amplification in Ra.
As terms used in Ra is dependent on the machine implementation there isn’t that much we can do w.r.t changing the format of the data.
I do appreciate that the deallocation work needs to be done. One thing I did think about is whether the order of items in the delayed dealloc queue has any bearing on the amount of work done.
For example:
Say a scheduler allocates a set of binaries and these are then deleted (freed) by some other scheduler in quick succession (or even by the same scheduler). Does the order of “deletes” affect how efficiently the allocators work? E.g. if we freed the binaries in the order or reverse order they were allocated would this have any effect. It is hard to measure by experiment as it is delayed of course.