How to do/build auto increment keys in erlang ets tables?
I have two ets sets tables for fast key value lookup in constant time. I need the two tables to be linked like this:
KEY FIELD VALUE FIELD
table1: {tuple data} unique number
table2: unique number {tuple data}
Is there a way to do auto increment in table2 when inserting a new row? Or do I have to do “bookkeeping” my self to track next key field number?
One of the greatest features of ets is support for counters There’s nothing automagic in that you must call the function, etc. but as the fine manual says, they are atomic and isolated
You’re not providing much detail, but some options are:
Use ets:info(T2, size) when inserting into T2. Assumes you’re not deleting from T2, except possibly the last entry (LIFO), and also assumes non-concurrent insertions. Concurrent insertions can be handled via a gen_server, or by using the options below.
Use erlang:unique_integer/0.
Using counters has been mentioned, but that seems like overkill to me.
If you need persistence between runtime instances then you need to store the counter in a file. Mnesia might help if you don’t want to roll your own “persistent integer”.
For our main servicing platform, KRED, yes we did. It’s on Aurora now. We do have one legacy system still on Mnesia, but that’s just on extended life support until we get the Ok to shut it down.
I will try to explain more: I am building an extended version of a distributed shared associative memory system inspired by the concept of Linda Tuplespace.
In this system a process can save data to the memory in form of a tuple. The tuple can contain any data and be of any length … {data1,data1,dataN…}.
This tuple of data is used as key in an ets set table (table1) so it is possible to retreive it again with an exact matc.
What I would like is in other ets table to be able to reference the tuple of data … not by its total value, but by an integer to avoid to many duplets of the tuple of data and thus save space in the system.
This is why I have another ets table (table2) refering (table1)
Optimally I would like an auto increment of the integer key when inserting a new row in table2 … so I dont have to keep track my self of the key index.
Hope my explanation makes sense … if not don’t hessitate to let me know and I will try and explain more
Right, that makes sense. Will this process handle concurrent writes? In other words, will a process wanting to insert data have to go through the process holding the ets table(s) or will the table be exposed such that any proc can come along and do an insert?
To be quite clear, the feature you originally asked about and AFAIK does not exist. You will have to handle incrementing a counter for a table yourself.
Also, other question, is this for just for funsies or ?
You are right, I don’t either think this feature exist. Right now I have build a solution where I handle the incrementing of the counter for the table myself. I was just courious if I had missed something and there might was a more elegant way around not having to increment the counter myself.
No it is not just funsies - It will be a new kind of a tuplespace implementation with high concurrent troughput. Still have some adjustment to make on the project … especially to (internally) make it transactionally safe whitout locking whole ets tables and make bottlenecks
Cool beans! So let me make a suggestion, but with little regard for concurrency issues you might face as whole (order, etc.).
As mentioned previously, atomic counters might be a perfect fit here. You can create a counter ref, and put in persistent term such that there’s not a huge penalty for fetching it, and what’s more the counters are guaranteed to be atomic and isolated and super fast.
What’s more if you need to persist this value, you can fetch it, stick it somewhere, etc. fetch it again, start up the counter with the value persisted, etc.
I hope this helps and I hope you tell us how this goes and if you found a better solution
As in, you want to have a “reference counter” for each tuple you store? E.g. {x, y z} is referenced 5 times, {x, k, m} is referenced 6 times? If that’s the case, you can just use ets:update_counter function, with your original tuple being a key.
Thank you for mention ets:update_counter - yes it will work since it is persistent i ets table :-), which I need for my application. Now I am already using a seperate ets table for the countervalue. This works nicely.
Main challenge is to secure consistency over the collection of involved ets tables when many processes access and changes values in them concurrently. Are implementing my own build of a software transaction mechanism right now without the need for locking whole tables, and thus becoming a bottleneck and degenerate the concurrent nature of the system.
Ahh! So the original suggestion was not off the mark (not completely anyway :p), but still a bit confused myself.
It sounded like in a follow up post you want a reference table, specifically a table that holds a reference to the original record (in table 1), that can be looked up via a unique sequential identifier (think sequence id in a relational database), such that you get back a reference that allows you to fetch the original record.
But it sounds like in your reply to @max-au you actually want to simply have reference counters.
I think final clarification would be great here, I’m quite interested
Also, if you indeed do want reference counters per Maxim’s reply, I’m not sure this method is going to save you any space. It depends.
It depends on exactly what these tuples will look like and how term sharing between two ets tables works (if there is any term sharing at all, I don’t know tbh).
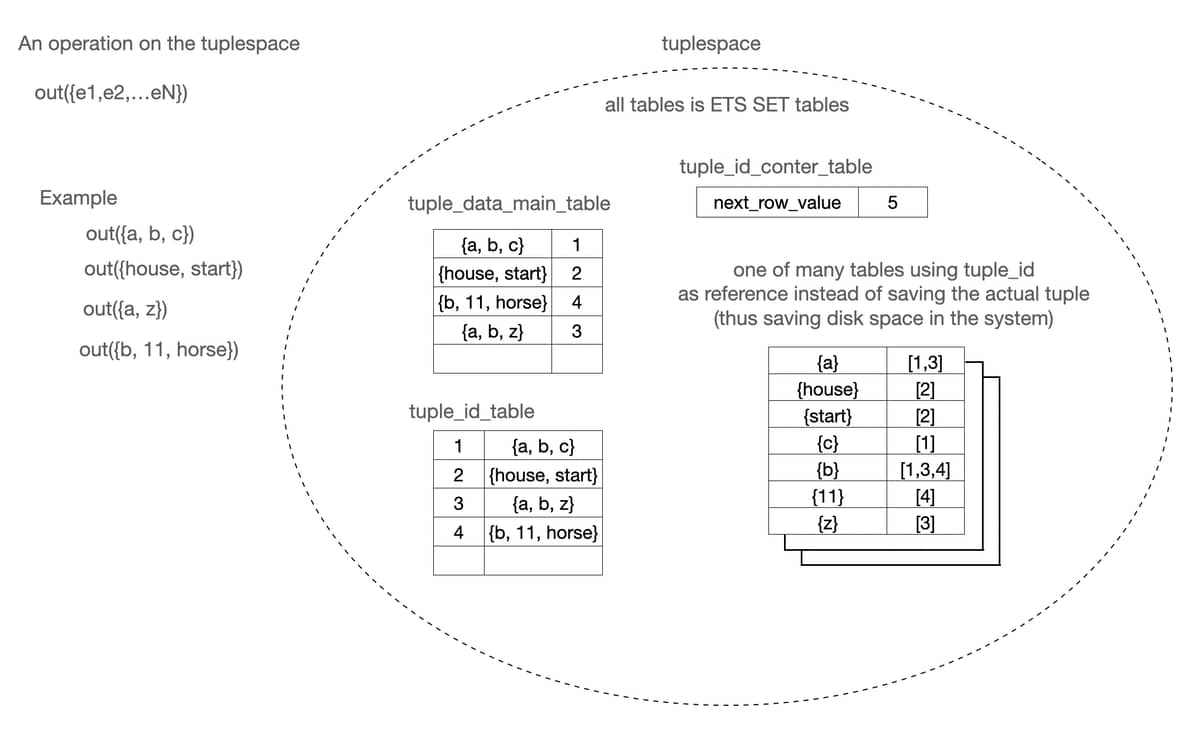
I have tried to explain it better - here is a graphical explanation of how I am using id’s to connect data in the system.
Let me know if there is questions or a way to avoid the persistent tuple_id_counter_table when inserting
new rows in tuple_id_table or tuple_data_main_table, or do it even better
What properties do your tuple ids need to maintain besides uniqueness? Of that’s it then guids are an obvious solution that requires no global state lookup.
Thank you for mentioning guids as a possible solution … I have totally forgot thinking about this as a possibillity.
The important properties of the tuple ids is:
guaranteed truly uniqueness
speed
memory conservation
The system is running in ram and needs to be able to work with ets tables populated with up to
1000.000.000’s of tuples. Right now it takes the system around 165 seconds to place 100.000.000 tuples in the tuplespace, with a memory usage of about 10GB for simple tuples.
I have limited experience with generating guids and how much memory they each take up, but I
think the solution I use now with just an integer value is better memory wise? On the flip side I have to do a little more work to make sure of consistency in the face of concurrent call to the tables.