Hi There,
This question related to my Erlang-Red project but is really its about how to store data efficiently in Erlang - bear with me here.
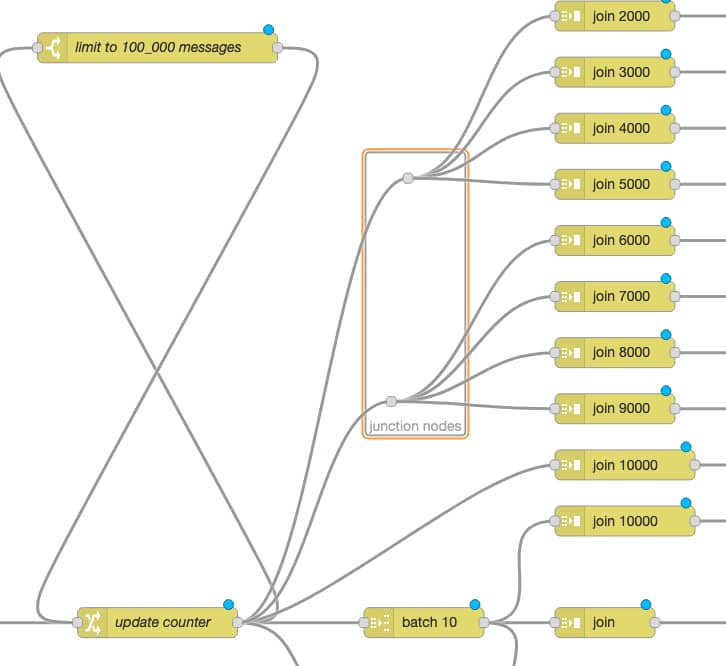
To demonstrate the question, two executions of the same flow. Top one is Erlang-Red, the bottom one is Node-RED. Both in real time, no speeding or slowing of frame rates and both using exactly the same flow.
Erlang-Red:
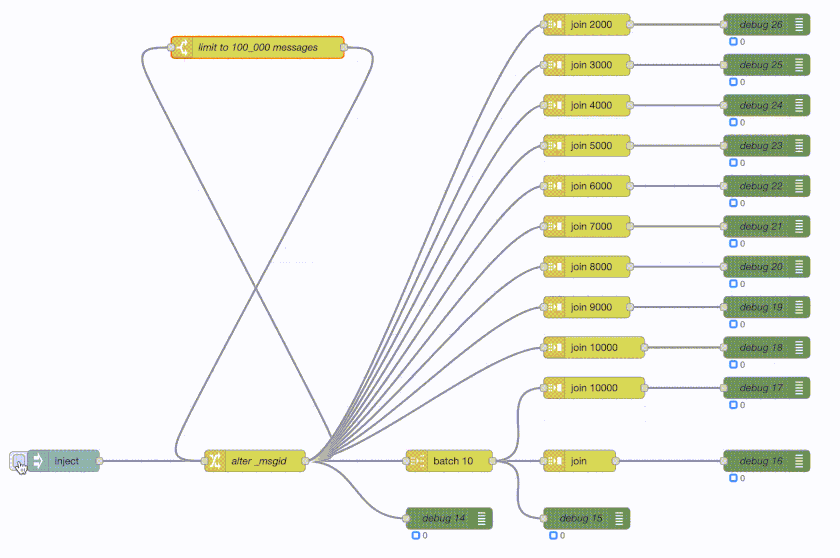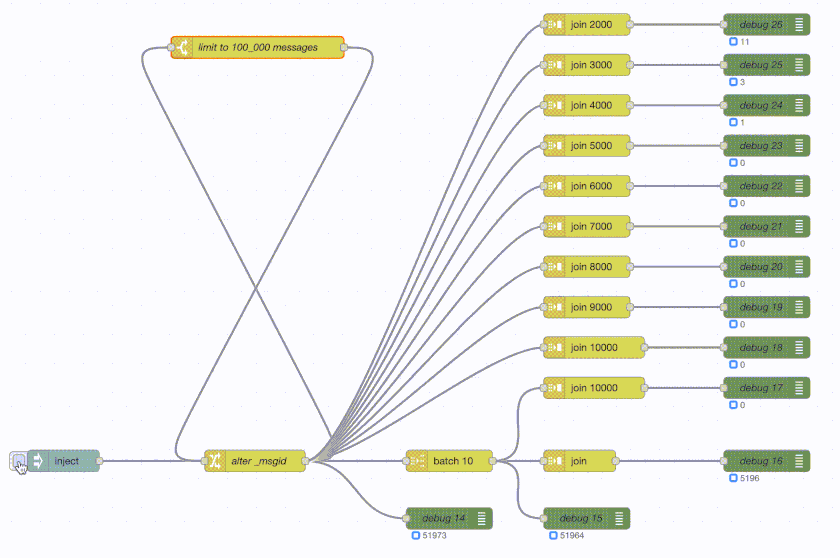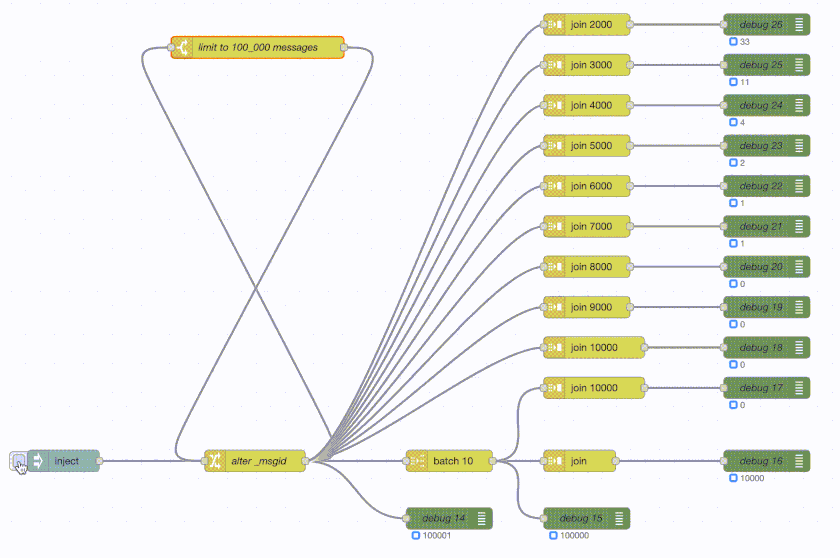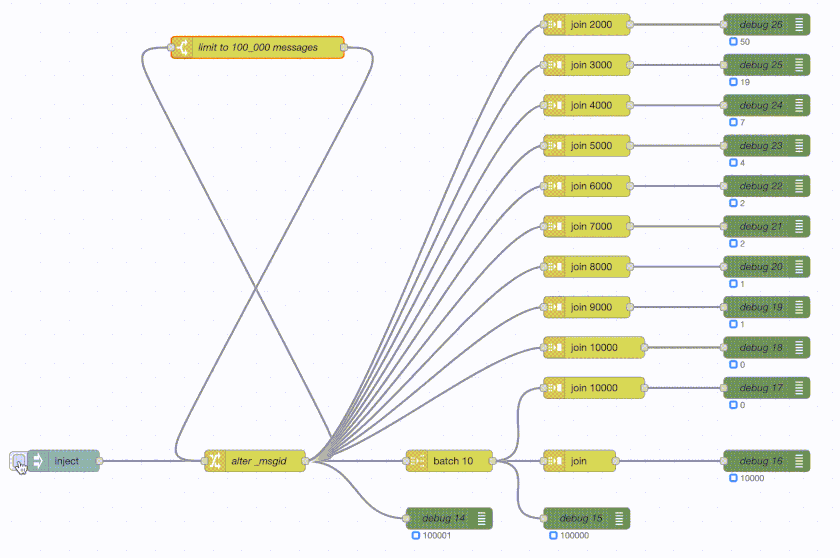
Node-RED:
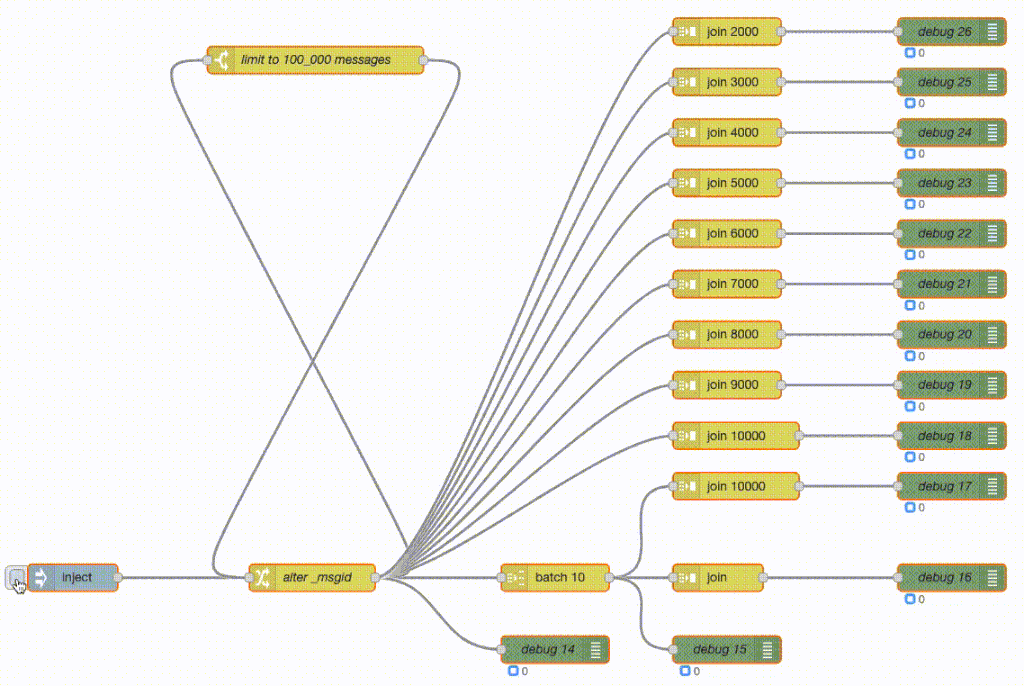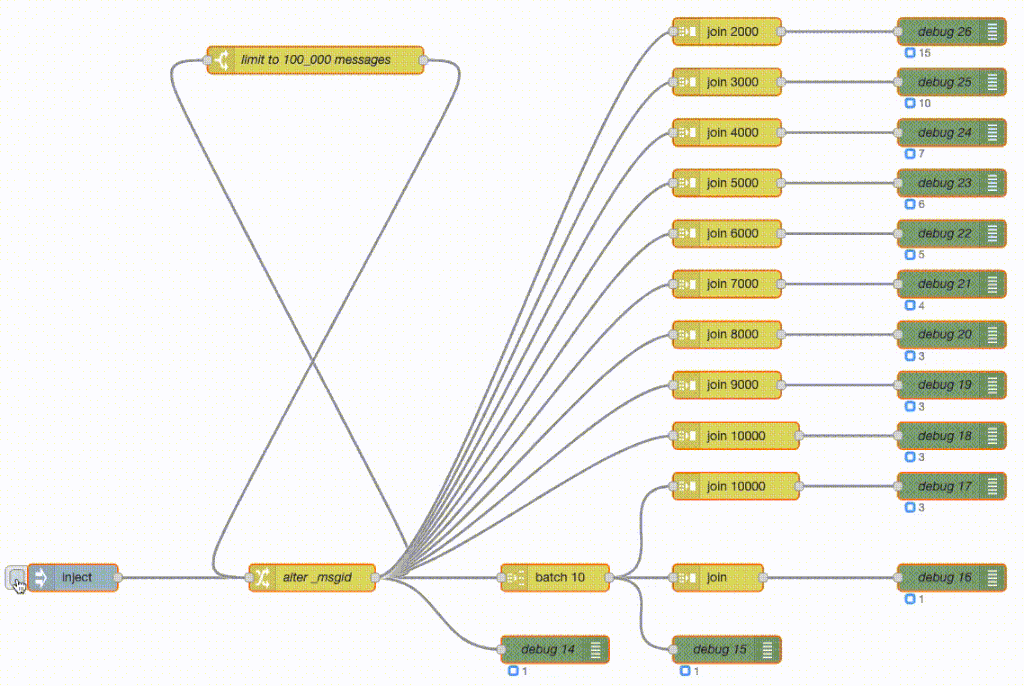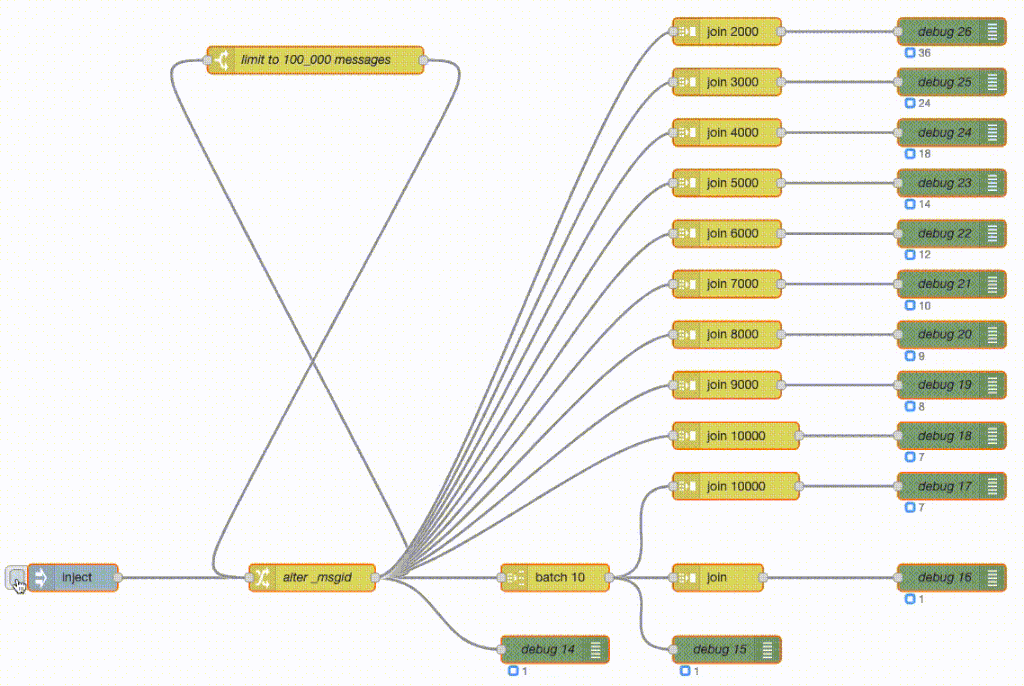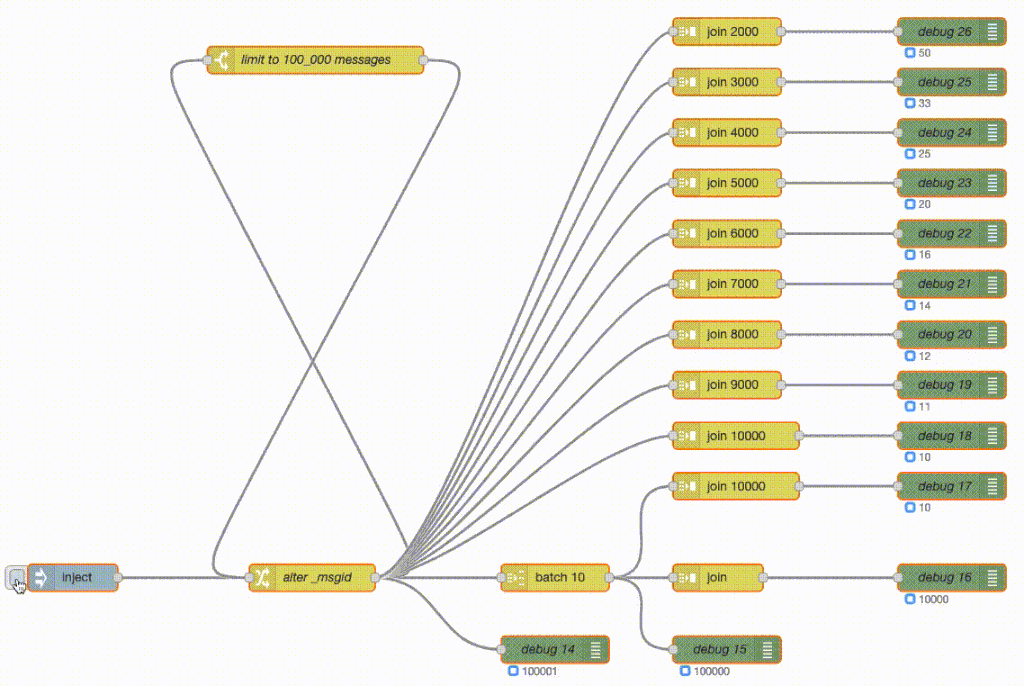
What the flow does is generate 100_000 messages and then do various forms of batching and joining. What a join node here does is wait for X number of messages and then send a single batched message containing all those messages - so it’s buffering the messages as they arrive.
The green debug nodes are counting messages as they arrive. So the top join is buffering 2000 messages and then sends out a single message with those 2000 messages attached. The debug counter shows 50 at the end as 100_000 / 2_000 = 50. The join 3000 does the same but with 3000 messages and hence its debug counter shows 33 at the end. And so on.
Now the problem: Node-RED takes about 8 seconds to execute the entire flow. Erlang-Red takes about a minute to do the same. Same data, same flow, same logic, same machine.
Perhaps my implementation is really bad but the bottom flow, which is also handling the 100_000 messages works at a comparable rate - so it can’t be a general implementational issue.
What I found was that if I don’t store the messages in the join node, then its much faster. Of course that defeats the purpose. So my question is: how can I store the data efficiently?
Currently the implementation is using gen_server with a list of messages, i.e. #{ store => [Msg | Store]} becomes the state of the gen_server with each new message. Each join node is a gen_server process and each is receiving the message independently from other join nodes.
I read somewhere that Erlang is using a linked list as storage mechanism for lists. So a I thought I’d use Store ++ [Msg] instead but that made no difference. What made a difference was #{ store => [Msg]}, i.e. no storage - then the execution times were comparable but no storage is no answer!
Any tips greatly appreciated.