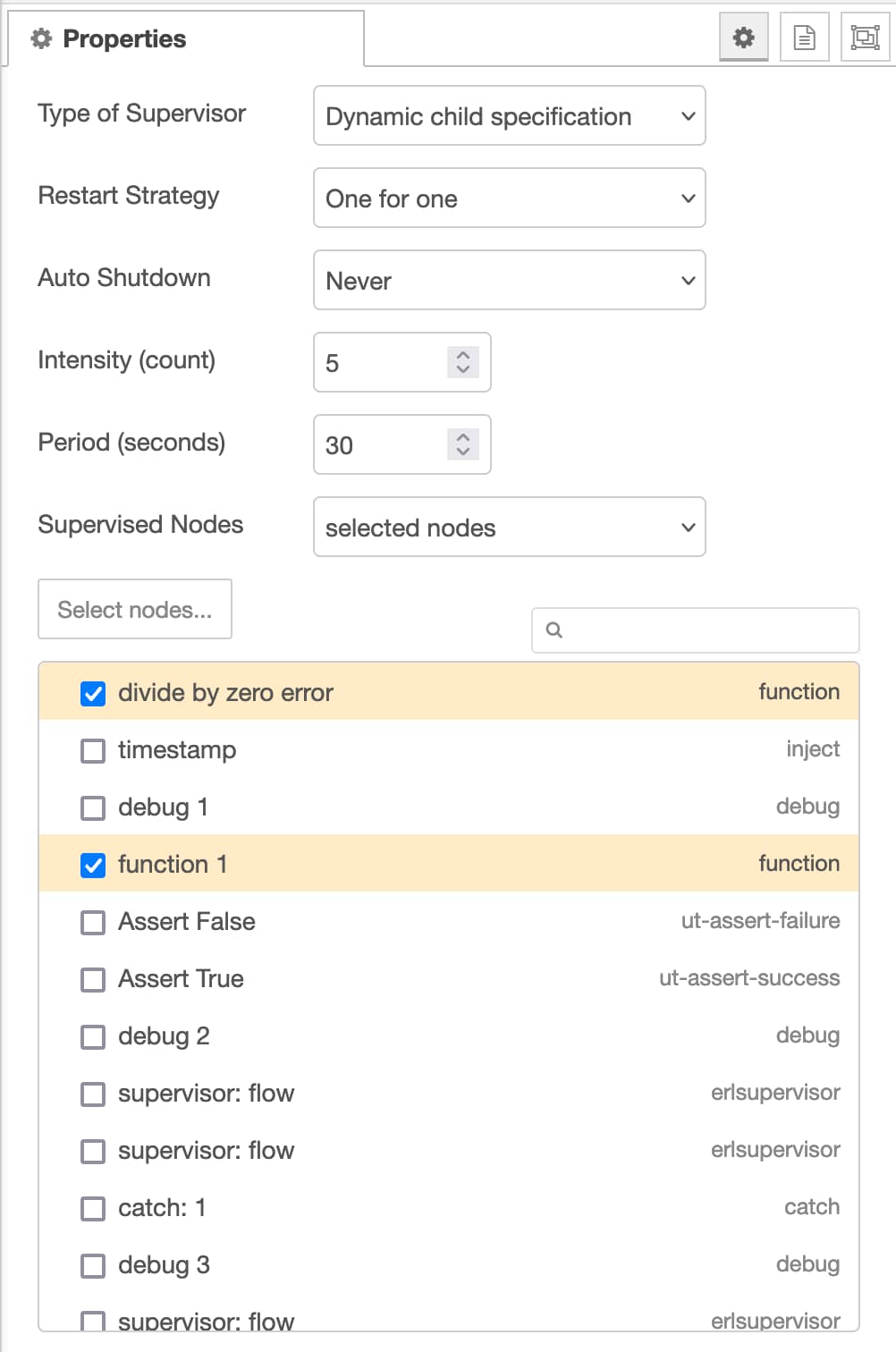
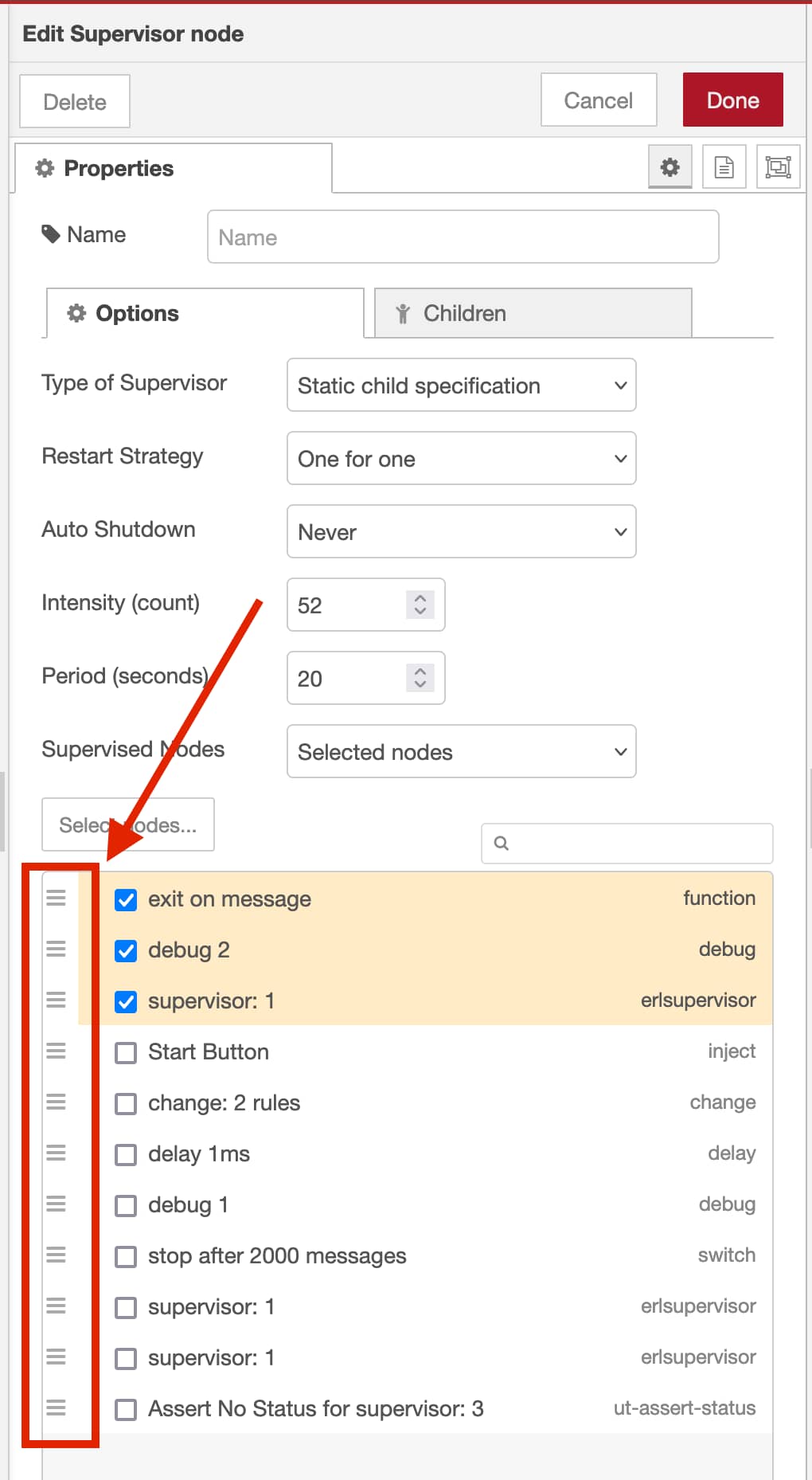
So the supervisor node works so far that I can visually demonstrate the differences between the restart strategies:
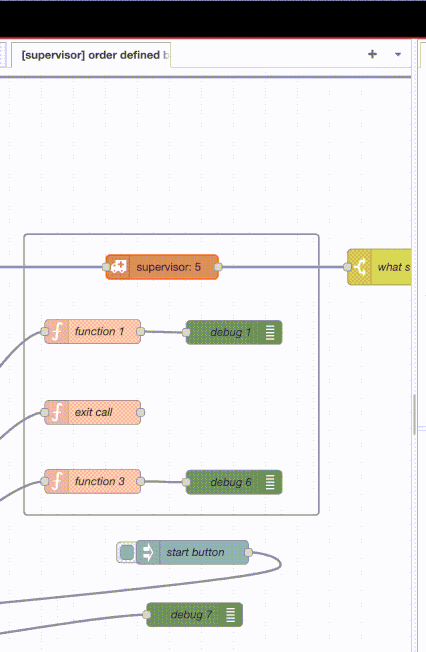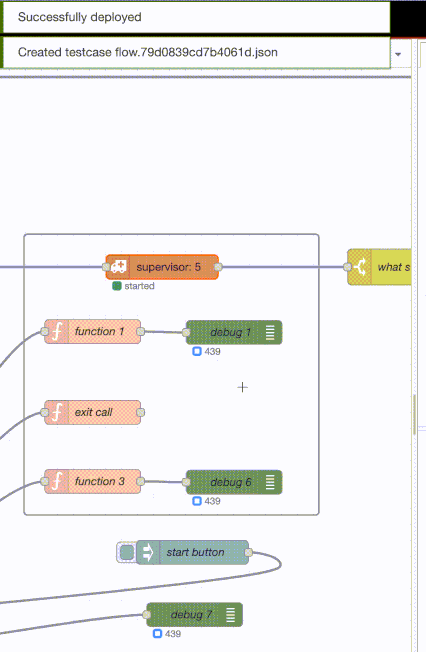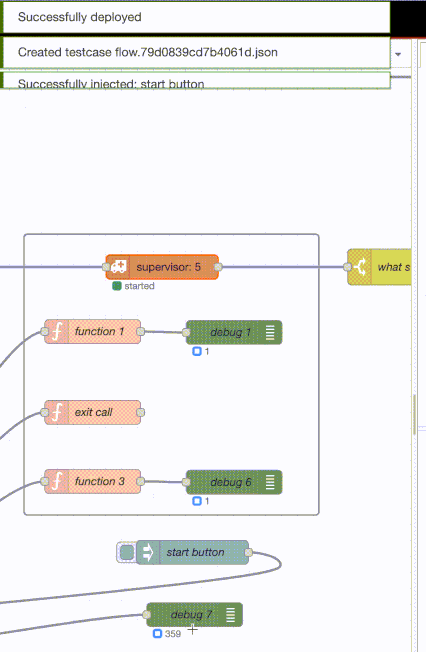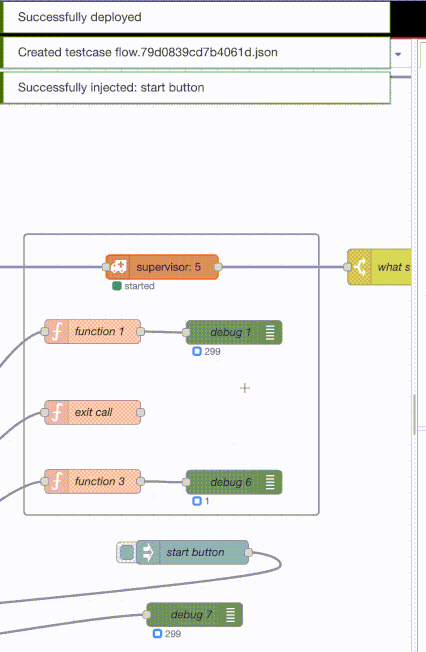
What is shown is a supervisor that is supervising three function nodes and two debug nodes. The debug nodes are just counting messages as they come in. The bottom and top function nodes just pass through the messages they receive and the middle function node does an exit(self()) - its the process/node that is failing.
The supervisor has an intensity of 500 over 30 seconds. Not shown is a message generator that is an infinite loop that pauses for 5 millisecond between messages. The debug node at the very bottom is counting those messages.
The order of the process - as given to the supervisor node - is defined by the ‘y’ coordinate of the nodes[1]. So the function 1 node is the first, then the debug 1 node, then the exit call function node (the one in the middle) and then the function 3 node and debug 6 node. Order is of course important for the rest-for-one option.
So what happens? When the first message comes in (all function nodes receive the same messages), the exit call function fails and the supervisor restarts it.
For one-for-all, all nodes are restarted. The debug nodes have their counts reset to zero and hence they are showing 1. It’s always a new message but they never get beyond one because the exit-call function keeps being restarted by the supervisor and so are they.
The one-for-one strategy shows the debug nodes hitting a message count of 501 because after 500 messages, the supervisor dies. What is not shown is that the supervisor is automagically restarted after two seconds (shown by the status of the supervisor node). When the supervisor is restarted, the processes that represent the function and debug nodes are restarted and begin receiving message from existing nodes/processes[2] again.
Finally the rest-for-one strategy shows that the top debug continues to receive messages (i.e. isn’t restarted) when the exit function is restarted but the debug 6 counter stays at 1 - because it’s being restarted.
The supervisor node sends out messages with status: started, restarted and dead are the three states it has. When a status of dead is received, a different flow sends the supervisor a message to restart itself and its children. This doesn’t have to happen, the supervisor can be left for dead, if so desired.
That’s the current implementation state of the supervisor node. I haven’t updated the codebase with the latest version, after all it’s Sunday! 
[1] = NOTE: this is for testing only, never, ever, will I use visual location to influence code logic - a very dark pattern and impossible to debug. Process order for the supervisor is still an open question on how best to do that.
[2] = Luckily I built ErlangRED such that when these processes are restarted, they have the same name as the before so that existing processes sending messages to named process simply continue to send their messages to the new processes, not even noticing that the process died inbetween.