The mnesia_rocksdb backend plugin offers support for very large disk-based tables in mnesia. It also offers a low-level access API, enabling efficient use of the Rocksdb access APIs while using Mnesia as the management framework: Tables are created via Mnesia, and can be access either using the low-level API or the normal Mnesia API.
We at QPQ AG are improving mnesia_rocksdb, in a new location:
Index plugins allow for derived index values, operating on the whole primary object
mnesia_rocksdb indexes are ordered sets
To efficiently traverse indexed tables, the mrdb_index module has provided fold and iterator functionality
With mrdb_index:select[_reverse](Tab, Ix, MatchSpec, [, Limit], the match spec operates on a set of tuples {IndexValue, ActualObject}, so that filtering can be done simultaneously on the index value and the object itself.
With structured index values, prefix matching is done on the bound prefix of the value, allowing for efficient searching.
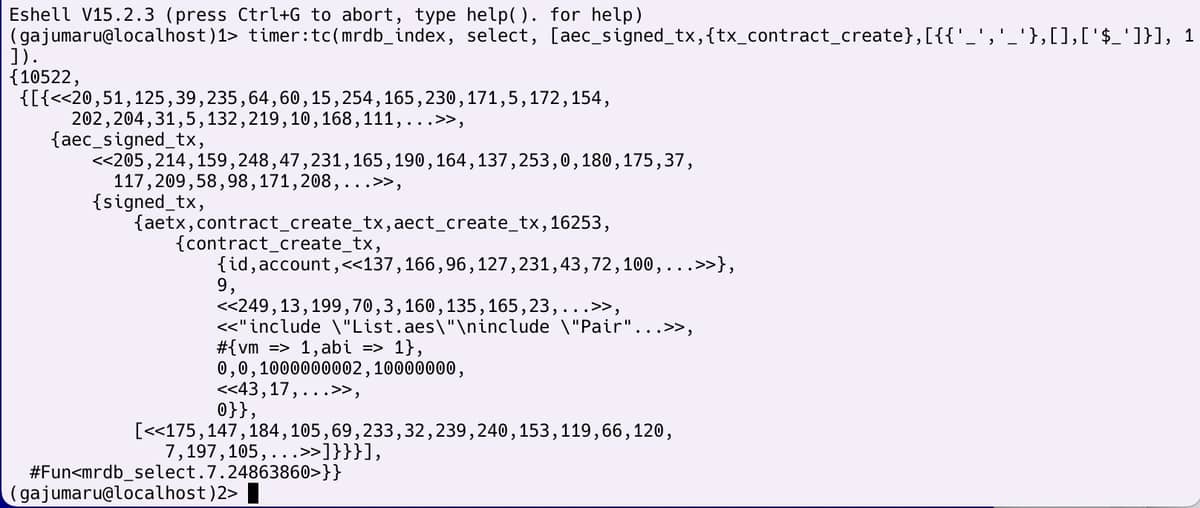
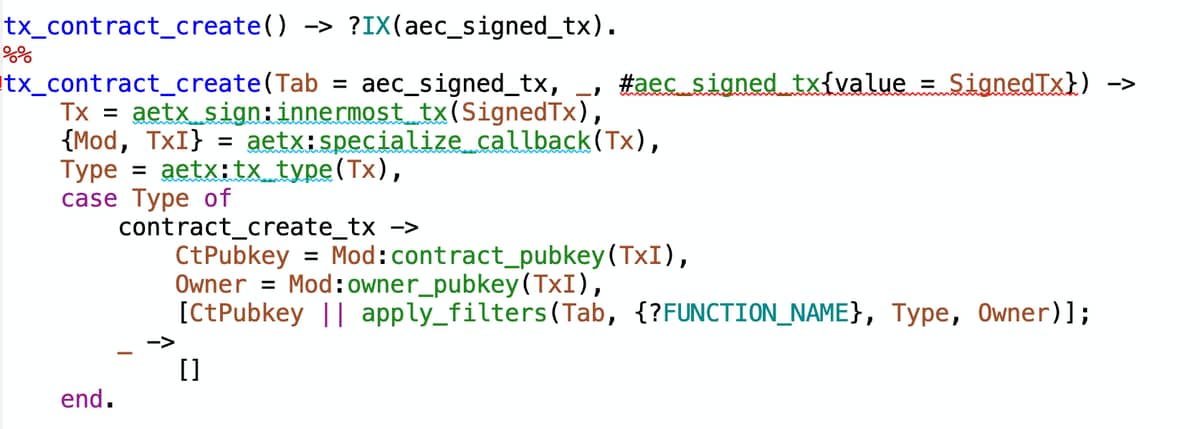
To illustrate the utility of this, here are some snaps from an indexing plugin in one of our blockchain nodes. The plugin uses the indexing plugin feature in Mnesia, registering callback functions that derive secondary keys from a given table. The callbacks can operate on the whole object.
In the example here, an index helps locate smart contract creation transactions. This particular transaction resided at height 141648 on the chain, so a sequential search had been unworkable. The select operation, combining an index traversal with object lookup, took ca 10 ms.
We moved from Mnesia to Khepri a couple years ago and are happy with it, but I’m exploring different approaches. The prefix key optimization and sext-based ordering look compelling for our query patterns.
Are there any comprehensive tutorials or real-world examples beyond the code snippets in the docs? I’m particularly interested in migration strategies, performance tuning, and applications that demonstrate the RocksDB backend at scale.
Any substantial applications or case studies you’d recommend looking at?
Thanks for the continued work on this!
Apart from the stuff I’ve written in the mnesia_rocksdb docs, in part trying to address some blind spots in the mnesia docs, I did give a presentation about mnesia_rocksdb, where I covered some consistency and performance issues, and explaining the approach to use mnesia mainly as scaffolding and then using a mnesia-like API against Rocksdb.
In terms of using Rocksdb at scale, there are some users out there that use RocksDb directly, i.e. not from Erlang. In the blockchain world, I guess the Ethereum blockchain is one of the biggest examples I know, with a total database size of ca 1TB, if you sync the whole blockchain. I believe most of the big implementations use LevelDB, but at least the Rust client uses Rocksdb.
In blockchains, the performance-critical part is when synching the database - i.e. catching up to the top from scratch. This can lead to very high write pressure, which gave us problems when viewing it as a simple backend and using the Mnesia transaction support. This is explained in the presentation above.
I would mainly recommend mnesia_rocksdb for single-node databases. While the backend plugin system does have hooks for more sophisticated table sync protocols, this is not something I’ve explored, since I’ve worked on blockchains for the last 7-8 years, and we have no use for that type of distribution.
The function works for all mnesia table types (although a bit faster for rocksdb copies). If you still want type safety, feel free to use a typed map in the match pattern. Any attribute not listed in the map gets assigned ’_’.
I have also added mrdb:select_reverse(Tab, MatchSpec [, Limit]), which I personally end up using a lot. This is mainly for those who choose to commit to using the mrdb API rather than the mnesia access API.
I’ve created a PR, bringing up our `mnesia_rocksdb` to the latest emqx version of `erlang-rocksdb`.
While testing it, I accidentally discovered failures in my test case ensuring that the abort returns under `mnesia_compatible` mode are structurally the same as when running `mnesia:activity/2` (this is to simplify migration, while keeping the default exception handling in mrdb more ‘modern’.)
I traced the change to the `mnesia-4.23.5.1` update. Given that OTP is typically very careful about communicating compatibility-breaking changes, and wouldn’t smuggle them in via a commit that doesn’t even warrant a patch version update (right, @dgud?), I imagine that this was inadvertent.
This was the OTP commit in question: Report stacktrace in non-transactions activity function errors. · erlang/otp@d63237b · GitHub
It’s a subtle change, and unless you specifically match on abort reasons, you wouldn’t notice.